
Key Words:
Sentiment Analysis, Natural Language Processing (NLP), Emotional Tracking
Tools:
Python(Plotly, TextBlob, VADER), Google Cloud Natural Language API, GitHub Pages, VS Code
Project Overview
This project uses Natural Language Processing (NLP) to explore how emotions evolve across therapy sessions by analyzing transcripts from the HBO series In Treatment. By applying three different sentiment analysis models—TextBlob, VADER, and Google Cloud NLP—I built an interactive visualization to compare how these tools interpret emotional tone. The goal is to provide therapists, researchers, or viewers with a way to examine dialogue patterns and emotional turning points objectively.
Research Goal
Coming from a background as a clinical psychologist, I know how central emotional shifts are to the therapeutic process. In most psychotherapy sessions, therapists rely heavily on their own intuition and experience to interpret the patient’s emotional state and guide the direction of treatment.
But what if we had a tool that could objectively analyze the emotional tone of each therapy dialogue—highlighting spikes, shifts, or moments of emotional flatness? Such a tool could help therapists identify potential breakthroughs, overlooked tensions, or topics worth revisiting. It could also provide valuable feedback for patients themselves, encouraging deeper self-awareness and reflection.
This project explores whether sentiment analysis models can offer a new lens on therapy conversations—enhancing, rather than replacing, human judgment.
Research Question
Can NLP help therapists and clients better understand emotional shifts during therapy? More specifically:
- How do different sentiment models vary in detecting emotional shifts in therapy dialogue?
- Can these tools offer useful insights to therapists or clients, especially in identifying emotional turning points?
These questions aim to evaluate whether computational tools can offer meaningful support in therapy contexts—both as reflective aids for clients and as analytical resources for therapists.
Methodology
Data Source:
To avoid privacy concerns associated with real-life therapy transcripts, this project uses dialogue from the HBO series In Treatment as a proxy. The show takes place almost entirely within therapy sessions, with each episode representing a single session. I focused on six sessions centered on the character Laura.
Subtitle files (SRT format) were sourced from OpenSubtitles.org, which include only dialogue text and timestamps. Speaker identification was added manually with the help of the AI transcription tool Otter and further verified through manual review.
Sentiment Analysis Tools:
TextBlob – A lexicon-based tool that assigns polarity scores to each sentence based on predefined word sentiment values. It works by computing the average score of all recognized words in a sentence.
I chose TextBlob because it is a fundamental NLP tool suitable for short text and offers a transparent and interpretable baseline for sentiment scoring.

VADER – A rule-based model specifically tuned for social and conversational text. It builds on a predefined sentiment dictionary but includes heuristics that account for capitalization, punctuation, and degree modifiers (e.g., “REALLY amazing!”).
I used VADER because it is likely to outperform basic lexicon models like TextBlob in dialogue settings due to its specialized design for informal text.

Google Cloud Natural Language API – A machine learning-based sentiment analyzer trained on a vast dataset of human language. It considers broader linguistic context and provides sentence-level sentiment scores.
I included this tool to represent a more advanced, cloud-based commercial sentiment engine known for its accuracy and adaptability, allowing for contrast with the simpler, local tools.

Each sentence was fed into the three tools, and scores were recorded ranging from -1 (very negative) to +1 (very positive).
Visualization Tool:
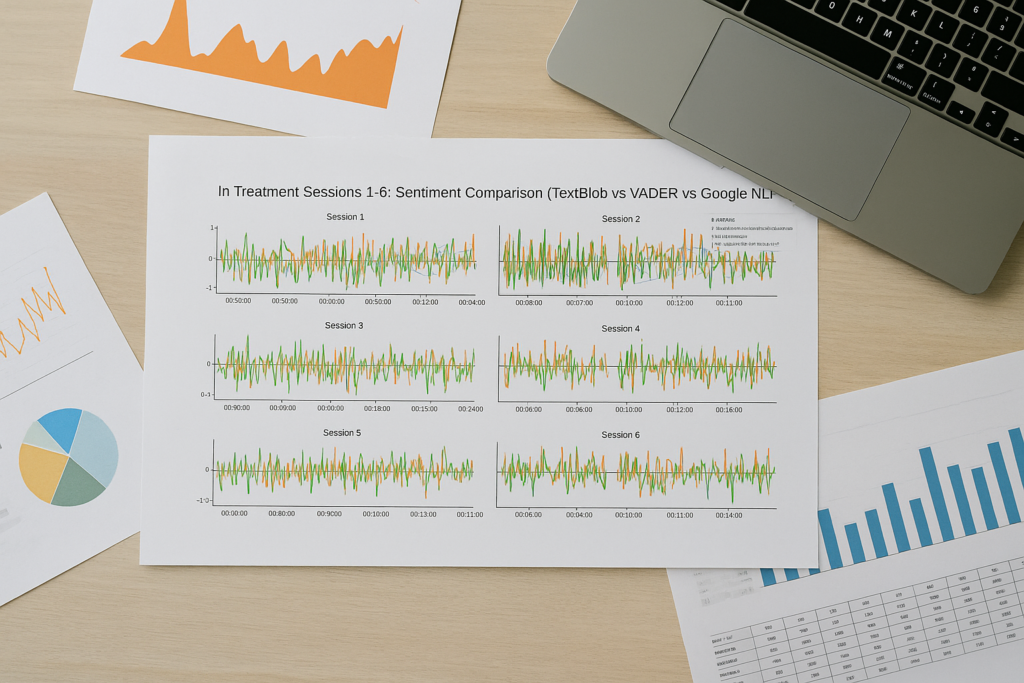
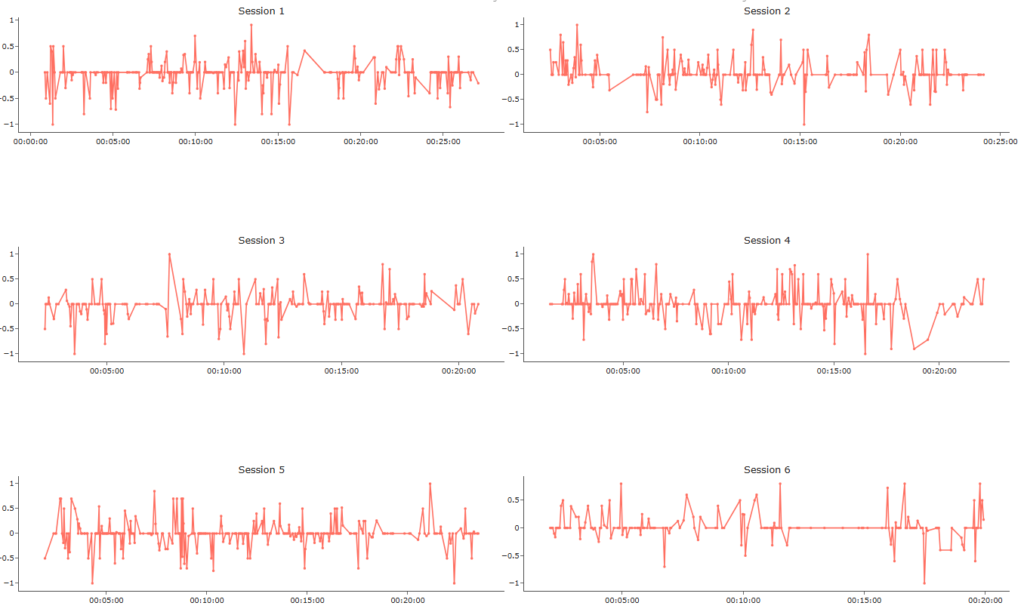
Plotly was used to build an interactive multi-panel line chart, showing sentiment trends across all six sessions. Each panel corresponds to one session and shows separate lines for Paul and Laura, for each sentiment model.
Visualization Highlights & Key Findings
View the Full Visualization
Interactive Chart Structure Overview

This section shows the top portion of the interactive visualization. Just below the title is a legend, which allows users to selectively display or hide sentiment lines for each speaker and model. The chart is arranged in a multi-panel layout, with each row showing two therapy sessions side by side.
In the upper-right corner, users will find built-in chart controls for zooming, resetting the view, and exporting. To enhance usability, I also added a floating “Chart Tips” box that explains key features—such as how to toggle line visibility via the legend or how to zoom in on specific areas. This helps users engage with the chart more intuitively.
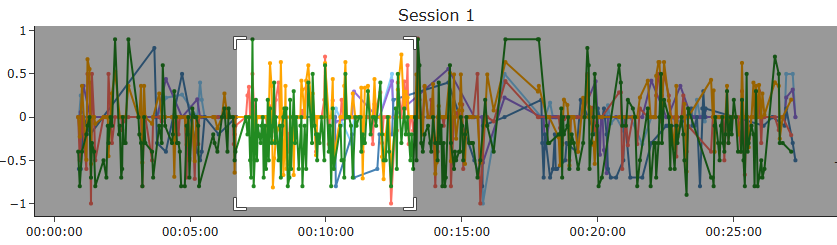
Users can interact with the chart by clicking and dragging to zoom into areas of interest. For example, in Session 1, users can highlight a specific time range and instantly focus on that portion of the emotional trajectory. Additionally, hovering over any point reveals a tooltip containing the exact sentence and its sentiment score. These interactive features allow for detailed inspection of emotional fluctuations within any given moment in a session.

Interpreting the Findings
Because emotional tone is inherently subjective, different people might interpret the same sentence as either positive or negative depending on context, tone, and personal experience. For this reason, I chose not to embed my own commentary or annotations directly in the interactive chart. Instead, I offer some of my interpretations here—separately—so users can freely explore the visualization and form their own insights without bias.
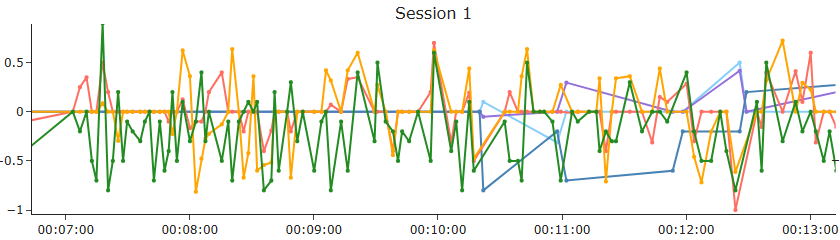
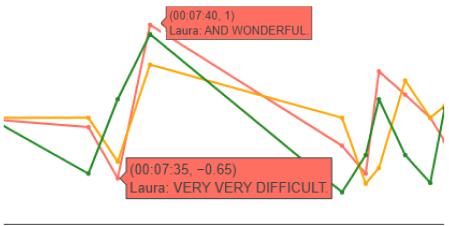
Overall, when the emotional expression is explicit and unambiguous, all three sentiment analysis models tend to agree on the polarity. For instance, in the excerpt shown here, the phrase “VERY VERY DIFFICULT” was interpreted as clearly negative, while “AND WONDERFUL” was consistently scored as positive across TextBlob, VADER, and Google Cloud NLP. This suggests that in cases of strong and straightforward emotional language, the models align well despite their different underlying mechanisms.
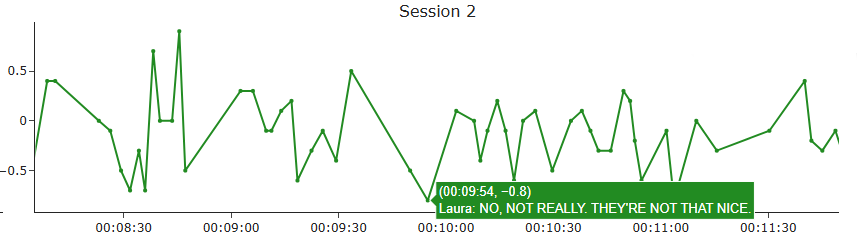
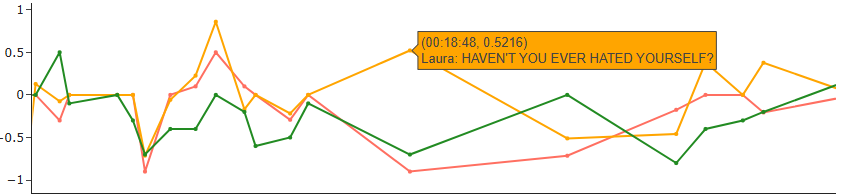
Although relatively rare, there are instances where the sentiment polarity differs across models—usually due to one model misinterpreting the context. In the example shown here, Laura asks “HAVEN’T YOU EVER HATED YOURSELF?” Subjectively, I would consider this sentence neutral to slightly negative. Google Cloud NLP returns a moderately negative score, which aligns with this interpretation. TextBlob gives a strongly negative score, likely influenced by the word “hated.”
The more surprising result comes from VADER, which assigns a positive sentiment. One possible explanation is the punctuation: VADER’s rules sometimes treat rhetorical questions or emphasis markers (like “?”) as emotional intensifiers or polarity shifters. Additionally, because all subtitles are in uppercase (due to their origin in subtitle files), VADER loses the ability to use capitalization as a cue for emphasis. This might further reduce its accuracy in detecting emotional tone in this specific format.
From a therapeutic perspective, aside from comparing models, one might expect to see emotional fluctuations decrease over time as therapy progresses—indicating increased emotional stability or therapeutic improvement.
Looking specifically at Laura’s sessions, her emotional line appears somewhat smoother in the final session (Session 6) compared to earlier ones. However, it’s important to note that their therapy ended abruptly in that session due to emotional complications between patient and therapist. As such, it’s difficult to interpret this trend as clear therapeutic progress.
Reflection & Limitations
Model-Generated Sentiment:
The sentiment scores in this project are generated entirely by algorithms. While they provide a helpful approximation of emotional tone, they do not reflect an individual’s actual mental state or clinical condition. These models interpret language patterns, not psychological nuance or therapeutic intent.
Differences in Scoring Scale Across Models:
Each sentiment analysis model uses its own logic and scoring range. For example, TextBlob tends to produce more extreme scores, VADER often yields more neutral values, and Google NLP applies a context-aware scoring system. Because of these fundamental differences, their numerical sentiment scores should not be compared directly.
However, comparing the polarity direction—whether a sentence is interpreted as positive or negative—still offers meaningful insights into how different tools interpret tone.
Limits of Context Awareness:
TextBlob and VADER evaluate sentences independently, without considering the surrounding dialogue. While Google Cloud NLP includes some contextual understanding via machine learning, it still processes each sentence in isolation and returns a single score per line.
In this project, I intentionally adopted a sentence-level approach in order to visualize emotional variation across time using a line chart. However, for a deeper and more holistic understanding of therapeutic dialogue, large language models (LLMs) such as ChatGPT may be better suited. One promising future direction could involve having an LLM interpret the overall emotional flow of a session, then retroactively assign sentiment scores to individual sentences. This might produce a more contextually accurate and therapeutically meaningful output.
Explore or Reproduce This Project
The full project is available on GitHub, including all code, sample data, and the interactive visualization.
If you’re interested, you’re welcome to reproduce the analysis using my dataset—or better yet, apply the workflow to your own dialogue transcripts. This is a flexible, open framework designed to explore emotional patterns in conversation using NLP tools and visualizations.
Please note:
The Google Cloud NLP API requires an API key and setup through Google Cloud Platform. While Google offers 5,000 free requests per month, users will need to create their own API credentials to access this feature.
The other two tools—TextBlob and VADER—can be used immediately with standard Python packages, no additional setup required.